PERIOD VITS: VARIATIONAL INFERENCE WITH EXPLICIT PITCH MODELING FOR END-TO-END EMOTIONAL SPEECH SYNTHESIS
Authors
Yuma Shirahata
Ryuichi Yamamoto
Eunwoo Song
Ryo Terashima
Jae-Min Kim
Kentaro Tachibana
Paper
Submitted to ICASSP 2023
arXiv: TBD
Abstract
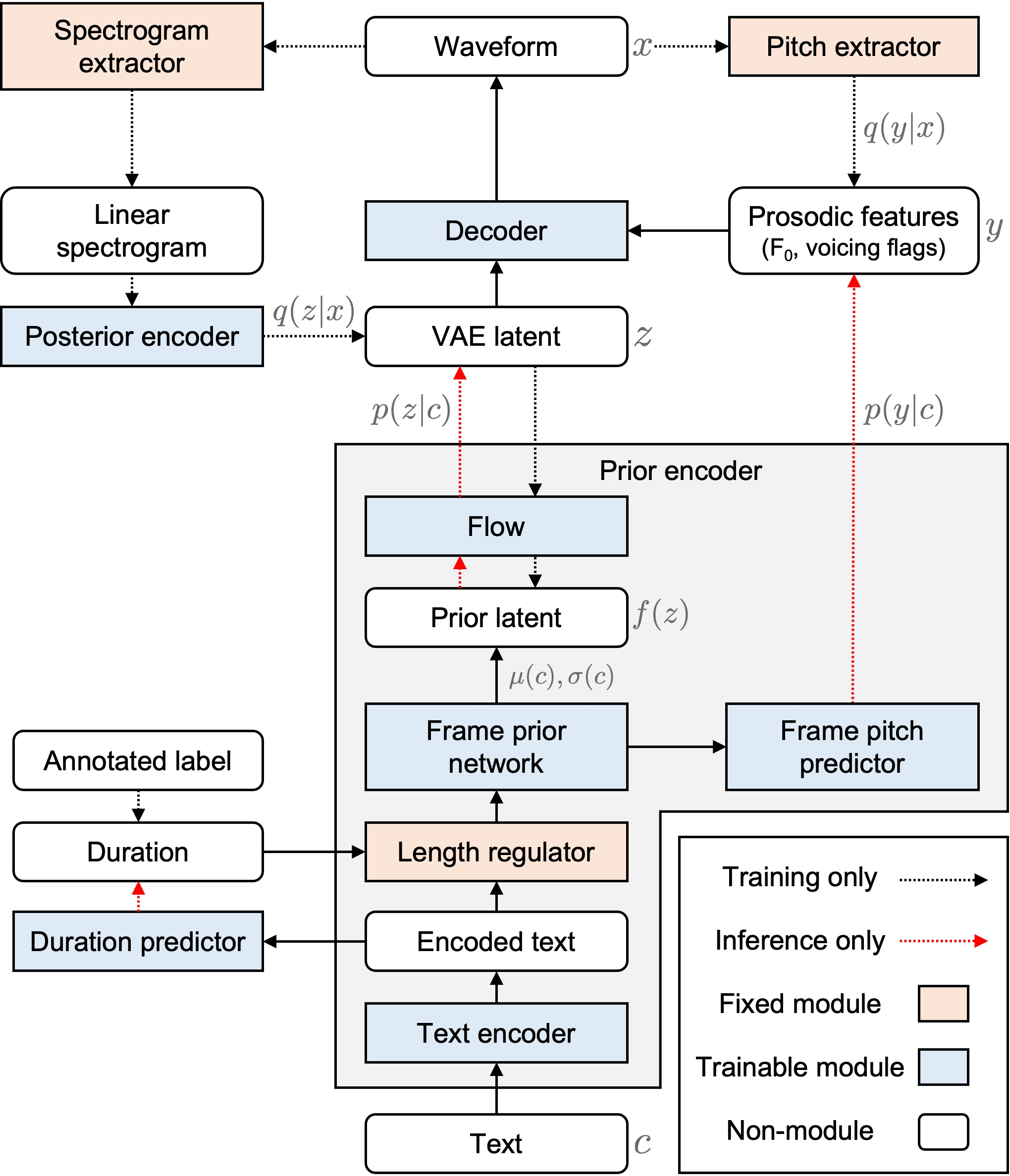
Several fully end-to-end text-to-speech (TTS) models have been proposed that have shown better performance compared to cascade models (i.e., training acoustic and vocoder models separately). However, they often generate unstable pitch contour with audible artifacts when the dataset contains emotional attributes, i.e., large diversity of pronunciation and prosody. To address this problem, we propose Period VITS, a novel end-to-end TTS model that incorporates an explicit periodicity generator. In the proposed method, we introduce a frame pitch predictor that predicts prosodic features, such as pitch and voicing flags, from the input text. From these features, the proposed periodicity generator produces a sample-level sinusoidal source that enables the waveform decoder to accurately reproduce the pitch. Finally, the entire model is jointly optimized in an end-to-end manner with variational inference and adversarial objectives. As a result, the decoder becomes capable of generating more stable, expressive, and natural output waveforms. Theexperimental results showed that the proposed model significantly outperforms baseline models in terms of naturalness, with improved pitch stability in the generated samples.
Demo
Systems
The table below summarizes the systems for comparison. E2E: end-to-end model. FPN: frame prior network in VISinger [1]. FS2: FastSpeech2 [2]. P-VITS: Period VITS (i.e. Our proposed model). *: Not the same but a similar architecture.
Model
Type
Duration input
FPN
Pitch input
Periodicity generator input
VITS [3]
E2E
No
No
None
-
FPN-VITS
E2E
Yes
Yes
None
-
CAT-P-VITS
E2E
Yes
Yes
Frame-level to decoder
-
Sine-P-VITS
E2E
Yes
Yes
Sample-level to decoder
Sine-wave
P-VITS
E2E
Yes
Yes
Sample-level to decoder
Sine-wave + V/UV + noise
FS2+P-HiFi-GAN [4]
Cascade
Yes
*
Sample-level to decoder
Sine-wave + V/UV + noise
Audio samples (Japanese)
Neutral style
Model
Sample 1 (Female)
Sample 2 (Male)
Reference
VITS
FPN-VITS
CAT-P-VITS
Sine-P-VITS
P-VITS
FS2+P-HiFi-GAN
Happiness style
Model
Sample 1 (Female)
Sample 2 (Male)
Reference
VITS
FPN-VITS
CAT-P-VITS
Sine-P-VITS
P-VITS
FS2+P-HiFi-GAN
Sadness style
Model
Sample 1 (Female)
Sample 2 (Male)
Reference
VITS
FPN-VITS
CAT-P-VITS
Sine-P-VITS
P-VITS
FS2+P-HiFi-GAN
Acknowledgements
This work was supported by Clova Voice, NAVER Corp., Seongnam, Korea.
References
[1]: Yongmao Zhang, Jian Cong, Heyang Xue, Lei Xie, Pengcheng Zhu, and Mengxiao Bi, “Visinger: Variational inference with adversarial learning for end-to-end singing voice synthesis,” in ICASSP, 2022, pp.7237–7241.
[2]: Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao and Tie-Yan Liu, “FastSpeech 2: Fast and high-quality end-to-end text-to-speech,” In Proc. ICLR, 2021.
[3]: Jaehyeon Kim, Jungil Kong, and Juhee Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” in Proc. ICML, 2021, pp. 5530–5540.
[4]: Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” in NeurIPS, 2020, pp. 17022–17033.